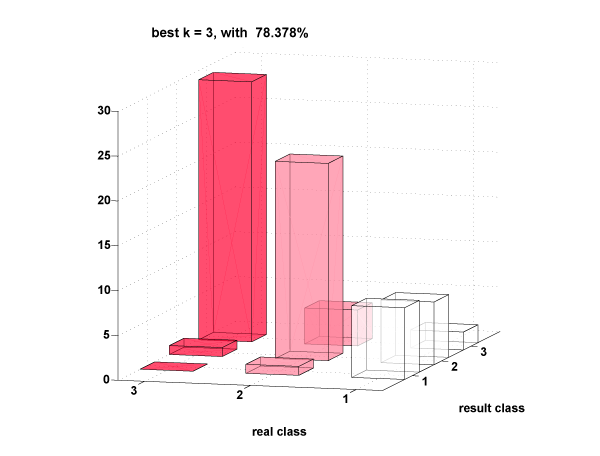
K-Nearest Neighbour
We ran knn with k = x (The best k was determined by cross-validation), and the best features were determined by an exhaustive search (all possible combinations of features). The results are detailed below.
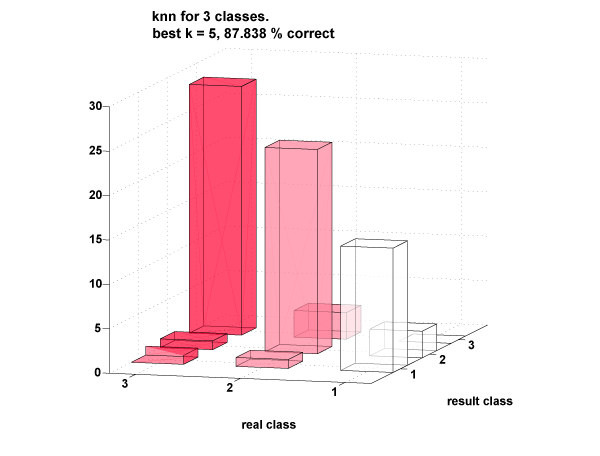
The misclassified points had waveforms that looked as if they belonged to other classes. Classification by humans was 100% incorrect in this case (the waveforms did not just look random, they looked similar to other classes).